













CMU Sphinx ╩Ūę╗┐Ņķ_į┤Īó├Ō┘MĄ─ųŪ─▄šZę¶ūRäe▄ø╝■ĪŻ╦³┐╔ęįė├ė┌ČÓĘN▓╗═¼Ą─ł÷║ŽĪŻšZę¶▐DõøĪóūų─╗ĪóšZčįĘŁūgĪó┬Ģę¶╦č╦„║═šZčįīW┴ĢĄ╚Ą╚Ż¼ę▓ę“×ķ╦³╩Ūķ_į┤Ą─Ż¼╦³į╩įS蹊┐╚╦åT║═ķ_░l╚╦åTĮ©┴óšZę¶ūRäeŽĄĮyĪŻÜgėŁ├Ō┘MŽ┬▌dŻĪ
CMU Sphinxėą──ą®╣”─▄
šZę¶ūRäe
ę¶Ņl▐Dõø
ś╦Ņ}ī”²R
IVR
╬─ūų▐DšZę¶
CMU Sphinxį§├┤ė├
Į©┴óšZčį─Żą═
ėąÄūĘNŅÉą═Ą──Żą═├Ķ╩÷šZčįūRäeĪ¬Ī¬ĻPµIūų┴ą▒Ē,šZĘ©║═ĮyėŗšZčį─Żą═,šZ궥─ĮyėŗšZčį─Żą═ĪŻ ─Ń┐╔ęį▀xō±╚╬║╬ĮŌ┤aĘĮ╩ĮĖ∙ō■─·Ą─ąĶŪ¾,─Ń╔§ų┴┐╔ęįį┌▀\ąąĢr─Ż╩Įų«ķgŪąōQĪŻ
ĻPµIūų┴ą▒Ē
Pocketsphinxų¦│ųĻPµIūųČ©╬╗─Ż╩Į,─·┐╔ęįųĖČ©ę¬▓ķšęĻPµIūų┴ą▒ĒĪŻ ▀@ĘN─Ż╩ĮĄ─ā׳c╩Ū,─Ń┐╔ęįųĖČ©ę╗éĆķōųĄ×ķ├┐éĆĻPµIūų,ĻPµIūų┐╔ęį▀B└mšZę¶ųą░l¼FĪŻ ╦∙ėąŲõ╦¹─Ż╩ĮīóįćłDÅ─šZĘ©Öz£yĄ─įÆ╝┤╩╣─Ń╩╣ė├Ą─įÆ,ø]ėąšZĘ©ĪŻ ĻPµIūų┴ą▒Ē┐┤ŲüĒŽ±▀@śė:
oh mighty computer /1e-40/
hello world /1e-30/
other phrase /1e-20/
ķōųĄ▒žĒÜųĖČ©├┐ę╗éĆČ╠šZĪŻ Ą╚▌^Č╠Ą─Č╠šZ┐╔ęį╩╣ė├▌^ąĪĄ─ķōųĄ1 e 1,▒žĒÜĖ³┤¾Ė³ķLĢrķgķōųĄĪŻ ╝┘Š»ł¾ķōųĄ▒žĒÜš{š¹ŲĮ║Ō,Õe▀^┴╦Öz£y,š{š¹ķōųĄĄ─ūŅ╝čĘĮĘ©╩Ū╩╣ė├ę╗éĆŅAŽ╚õøųŲĄ─ę¶Ņl╬─╝■ĪŻ
ūŅ║├Ą─Š½Č╚ūŅ║├ėąČ╠šZ3 - 4ę¶╣ØĪŻ ╠½Č╠Ą─Č╠šZ║▄╚▌ęū╗ņŽ²ĪŻ
ĻPµIūų┴ą▒Ēų¦│ųpocketsphinx,Č°▓╗╩Ūsphinx4ĪŻ
šZĘ©
šZĘ©├Ķ╩÷ĘŪ│Ż║åå╬ŅÉą═Ą─├³┴Ņ║═┐žųŲĄ─šZčį,║═╦¹éā═©│Ż╩Ū╩ųīæ╗“ūįäė╔·│╔Ą─┤·┤aĪŻ šZĘ©═©│Żø]ėąį~ą“┴ąĄ─Ė┼┬╩,Ą½ę╗ą®į¬╦ž┐╔─▄ųžĪŻ šZĘ©┐╔ęįäōĮ©JSGFĖ±╩Į║══©│ŻėąöUš╣ĪŻ ┐╦╗“.jsgfĪŻ
šZĘ©į╩įSŠ½┤_ųĖČ©┐╔─▄Ą─▌ö╚ļ,└²╚ń,─│ą®į~┐╔─▄ų╗ųžÅ═ā╔ĄĮ╚²┤╬ĪŻ ╚╗Č°,▀@ĘNć└Ė±┐╔─▄╩Ūėą║”Ą─,╚ń╣¹ė├æ¶▓╗ąĪą─╠°▀^Ą─įÆšZĘ©ę¬Ū¾ĪŻ į┌▀@ĘNŪķørŽ┬š¹éĆūRäeīóĢ■╩¦öĪĪŻ ę“┤╦ūŅ║├╩╣šZĘ©Ė³Ę┼╦╔,Č°▓╗╩ŪČ╠šZĄ─┤³ūėå╬į~┴ą▒Ēį╩įS╚╬ęŌĄ─Ēśą“ĪŻ ▒▄├Ō┼cįSČÓĘŪ│ŻÅ═ļsĄ─šZĘ©ęÄät║═ŪķørŽ┬,╦³ų╗╩Ū£pŠÅūRäeŲ„,┐╔ęį╩╣ė├║åå╬Ą─ęÄätĪŻ į┌▀^╚źĄ─šZĘ©ąĶę¬┤¾┴┐Ą─┼¼┴”š{š¹,š²┤_Ęų┼õūā«ÉĄ╚Ą╚ĪŻ ┤¾Ą─VXMLū╔įāąąśIĪŻ
šZčį─Żą═
ĮyėŗšZčį─Żą═├Ķ╩÷Ė³Å═ļsĄ─šZčįĪŻ ╦³éā░³║¼Ė┼┬╩Ą─į~║═į~Ą─ĮM║ŽĪŻ ▀@ą®Ė┼┬╩╣└ėŗĄ─śė▒ŠöĄō■,▓óūįäėėąę╗ą®ņ`╗ŅąįĪŻ └²╚ń,├┐éĆį~ģRĄ─ĮM║Ž╩Ū┐╔─▄Ą─,ļm╚╗▀@śėĄ─ĮM║ŽĄ─Ė┼┬╩┐╔─▄ėą╦∙▓╗═¼ĪŻ └²╚ń,╚ń╣¹─ŃäōĮ©ĮyėŗšZčį─Żą═Å─ę╗éĆå╬į~┴ą▒Ē,╦³īó╚į╚╗į╩įSĮŌ┤aį~ĮM║Ž▒M╣▄╦³┐╔─▄▓╗╩Ū─ŃĄ─ęŌłDĪŻ ┐éĄ─üĒšf,ĮyėŗšZčį─Żą══Ų╦]ūįė╔▌ö╚ļ,ė├æ¶┐╔ęįšf╚╬║╬ę╗éĆūį╚╗šZčį║═╦¹éāąĶę¬╣ż│╠╣żū„▒╚šZĘ©,─Ńų╗╩Ū┴ą│÷┐╔─▄Ą─ŠõūėĪŻ └²╚ń,─·┐╔─▄öĄūų┴ą▒ĒĪ░Č■╩«Ī▒║═Ī░╚²╩«╚²Ī▒║═ĮyėŗšZčį─Żą═īóį╩įSĪ░╚²╩«Ī▒ėąę╗Č©Ė┼┬╩ĪŻ
┐éĄ─üĒšf,¼F┤·šZę¶ūRäeĮė┐┌═∙═∙Ė³ūį╚╗,▒▄├ŌųĖō]┐žųŲĄ─╔Žę╗┤·’LĖ±ĪŻ ę“┤╦┤¾ČÓöĄĮń├µįOėŗĤŽ▓Ügūį╚╗šZčįūRäe┼cĮyėŗšZčį─Żą═▒╚é„ĮyĄ─VXMLšZĘ©ĪŻ
įOėŗų„Ņ}Ą─VUIĮė┐┌─Ń┐╔─▄Ėą┼d╚żĄ─Ģ°╚ńŽ┬: ūŅ║├╩Ūę╗éĆ║▄║├Ą─ÖC▒╚ē─╚╦:šZę¶ūRäe║═Ųõ╦¹═ŌüĒė├æ¶Įń├µė╔▓╝¶ö╦╣Balentine JetsonianĢr┤·Ą─ĪČ─║╣Ōų«│ŪĪĘ
ėą║▄ČÓĘĮĘ©┐╔ęįĮ©┴óĮyėŗšZčį─Żą═ĪŻ «ö─·Ą─öĄō■╝»║▄┤¾,ėą╩╣ė├CMUšZčįĮ©─Ż╣żŠ▀░³ĪŻ ąĪ─Żą═Ģr,─·┐╔ęį╩╣ė├ę╗éĆį┌ŠĆ┐ņ╦┘webĘ■äšĪŻ «ö─ŃąĶę¬╠žČ©Ą─▀xĒŚ╗“š▀─Ńų╗╩ŪŽļė├─ŃūŅŽ▓ÜgĄ─╣żŠ▀░³śŗĮ©ARPA─Żą═,─·┐╔ęį╩╣ė├╦³ĪŻ
šZčį─Żą═┐╔ęį┤µā”║═╝ė▌dį┌╚²éĆ▓╗═¼Ą─Ė±╩Į╬─▒Š ARPA Ė±╩Į,Č■▀MųŲĖ±╩Į▒Š║═Č■▀MųŲDMPĖ±╩ĮĪŻ ARPAĖ±╩ĮąĶę¬Ė³ČÓ┐šķg,┐╔ęįŠÄ▌ŗ╦³ĪŻ ARPA╬─╝■ .lm öUš╣ĪŻ Č■▀MųŲĖ±╩ĮąĶę¬┤¾┤¾£p╔┘┐šķg║═Ė³┐ņĄ─╝ė▌dĪŻ Č■▀MųŲ╬─╝■ .lm.bin öUš╣ĪŻ ę▓┐╔ęįį┌Ė±╩Įų«ķg▀Mąą▐DōQĪŻ DMPĖ±╩Į╩Ū▀^ĢrĄ─,▓╗═Ų╦]ĪŻ
Į©┴óę╗éĆšZĘ©
šZĘ©═©│Ż╩Ū╩ų╣żŠÄīæJSGFĖ±╩Į:
#JSGF V1.0;
/**
* JSGF Grammar for Hello World example
*/
grammar hello;
public <greet> = (good morning | hello) ( bhiksha | evandro | paul | philip | rita | will );
- PC╣┘ĘĮ░µ
- ░▓ū┐╣┘ĘĮ╩ųÖC░µ
- IOS╣┘ĘĮ╩ųÖC░µ
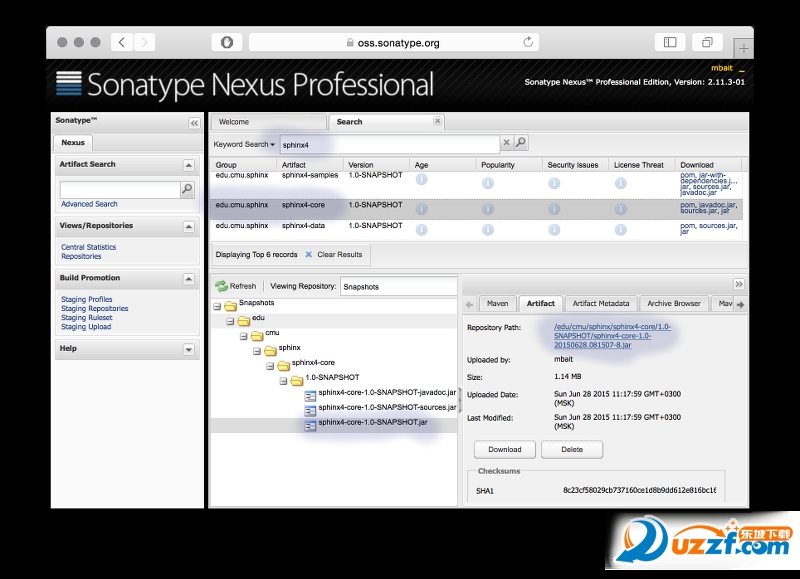

 Ž┬▌d
Ž┬▌d  Ž┬▌d
Ž┬▌d  Ž┬▌d
Ž┬▌d  Ž┬▌d
Ž┬▌d  Ž┬▌d
Ž┬▌d  Ž┬▌d
Ž┬▌d  Apifox(Apiš{įć╣▄└Ē╣żŠ▀)2.1.29.1 ŠG╔½░µ
Apifox(Apiš{įć╣▄└Ē╣żŠ▀)2.1.29.1 ŠG╔½░µ
 ąĪק²ö┤·┤a╣▄└Ē╣żŠ▀(TortoiseGit)2.13.0.1 ųą╬─├Ō┘M░µ
ąĪק²ö┤·┤a╣▄└Ē╣żŠ▀(TortoiseGit)2.13.0.1 ųą╬─├Ō┘M░µ
 SoapUIŲŲĮŌ░µ5.7.0 ūŅą┬░µ
SoapUIŲŲĮŌ░µ5.7.0 ūŅą┬░µ
 ąĪŲż├µ░Õ(phpstudy)8.1.1.3 ╣┘ĘĮūŅą┬░µ
ąĪŲż├µ░Õ(phpstudy)8.1.1.3 ╣┘ĘĮūŅą┬░µ
 Ruby3.0(ruby▀\ąąŁhŠ│)3.0.2 ╣┘ĘĮ░µ
Ruby3.0(ruby▀\ąąŁhŠ│)3.0.2 ╣┘ĘĮ░µ
 gccŠÄūgŲ„( MinGW-w64 9.0.0ŠG╔½░µ)├Ō┘MŽ┬▌d
gccŠÄūgŲ„( MinGW-w64 9.0.0ŠG╔½░µ)├Ō┘MŽ┬▌d
 īÜė±ŠÄ▌ŗų·╩ų0.0.05ą┬░µ
īÜė±ŠÄ▌ŗų·╩ų0.0.05ą┬░µ
 ╗╗©ŠÄ│╠▄ø╝■2.7.2 ╣┘ĘĮpc░µ
╗╗©ŠÄ│╠▄ø╝■2.7.2 ╣┘ĘĮpc░µ
 į│ŠÄ│╠╔┘ā║░Ó┐═æ¶Č╦3.1.1 ╣┘ĘĮ░µ
į│ŠÄ│╠╔┘ā║░Ó┐═æ¶Č╦3.1.1 ╣┘ĘĮ░µ
 Restorator 2009ųą╬─░µå╬╬─╝■Øh╗»░µ
Restorator 2009ųą╬─░µå╬╬─╝■Øh╗»░µ
 ╩«┴∙▀MųŲķåūxąĪ╣żŠ▀
╩«┴∙▀MųŲķåūxąĪ╣żŠ▀
 IT┤a▐r╣żŠ▀▄ø╝■1.0 ųą╬─├Ō┘M░µ
IT┤a▐r╣żŠ▀▄ø╝■1.0 ųą╬─├Ō┘M░µ
 python┼└ŽxīŹæ╚ļķTĮ╠│╠pdf├Ō┘M░µ
python┼└ŽxīŹæ╚ļķTĮ╠│╠pdf├Ō┘M░µ
 Postman Canary(ŠWĒōš{įć▄ø╝■)╣┘ĘĮ░µ7.32.0ŠG╔½├Ō┘M░µ
Postman Canary(ŠWĒōš{įć▄ø╝■)╣┘ĘĮ░µ7.32.0ŠG╔½├Ō┘M░µ
 ┤¾Č·║’╔┘ā║ŠÄ│╠┐═æ¶Č╦1.1.2 ╣┘ĘĮ├Ō┘M░µ
┤¾Č·║’╔┘ā║ŠÄ│╠┐═æ¶Č╦1.1.2 ╣┘ĘĮ├Ō┘M░µ
 excel┼·┴┐sqlšZŠõ(═©▀^excelśŗĮ©sql╣żŠ▀)1.0 ├Ō┘M░µ
excel┼·┴┐sqlšZŠõ(═©▀^excelśŗĮ©sql╣żŠ▀)1.0 ├Ō┘M░µ
 ▄ø╝■╠Ē╝ėÅŚ┤░║═ŠWųĘ╣żŠ▀1.0 ųą╬─├Ō┘M░µ
▄ø╝■╠Ē╝ėÅŚ┤░║═ŠWųĘ╣żŠ▀1.0 ųą╬─├Ō┘M░µ
 ╠ņ░įŠÄ│╠ų·╩ų2.1 å╬╬─╝■ųą╬─░µ
╠ņ░įŠÄ│╠ų·╩ų2.1 å╬╬─╝■ųą╬─░µ
 ida pro ųą╬─ŲŲĮŌ░µ(Ę┤ŠÄūg╣żŠ▀)7.0 ė└śĘØh╗»░µ64╬╗
ida pro ųą╬─ŲŲĮŌ░µ(Ę┤ŠÄūg╣żŠ▀)7.0 ė└śĘØh╗»░µ64╬╗
 VBA┤·┤aų·╩ų3.3.3.1╣┘ĘĮ░µ
VBA┤·┤aų·╩ų3.3.3.1╣┘ĘĮ░µ
 Node.jsķ_░līŹæĮ╠│╠░┘Č╚įŲ═Ļš¹░µĪŠ36šnĪ┐
Node.jsķ_░līŹæĮ╠│╠░┘Č╚įŲ═Ļš¹░µĪŠ36šnĪ┐
 į│ŠÄ│╠ļŖ─XČ╦3.9.1.347 ╣┘ĘĮPC░µ
į│ŠÄ│╠ļŖ─XČ╦3.9.1.347 ╣┘ĘĮPC░µ
 Ųč╣½ėó Android SDKV4.1.11 ╣┘ĘĮūŅą┬░µ
Ųč╣½ėó Android SDKV4.1.11 ╣┘ĘĮūŅą┬░µ
 Ųč╣½ėóiOS SDK2.8.9.1 ╣┘ĘĮūŅą┬░µ
Ųč╣½ėóiOS SDK2.8.9.1 ╣┘ĘĮūŅą┬░µ
 WxPythonųą╬─┐╔ęĢ╗»ŠÄ▌ŗŲ„1.2 ║å¾wųą╬─├Ō┘M░µ
WxPythonųą╬─┐╔ęĢ╗»ŠÄ▌ŗŲ„1.2 ║å¾wųą╬─├Ō┘M░µ
 Python┤·┤a╔·│╔Ų„1.0 ųą╬─├Ō┘M░µ
Python┤·┤a╔·│╔Ų„1.0 ųą╬─├Ō┘M░µ
 CšZčį┤·┤aīŹ└²ų·╩ų1.0 ├Ō┘M░µ
CšZčį┤·┤aīŹ└²ų·╩ų1.0 ├Ō┘M░µ
 c primer plusĄ┌6░µųą╬─░µĖ▀ŪÕ░µ
c primer plusĄ┌6░µųą╬─░µĖ▀ŪÕ░µ
 C++ Primer Plus 2021ļŖūė░µūŅą┬░µ
C++ Primer Plus 2021ļŖūė░µūŅą┬░µ
 notepad++7.8.2 ųą╬─├Ō┘M░µ
notepad++7.8.2 ųą╬─├Ō┘M░µ
 wpe pro Alpha 0.9a ųą╬─ŠG╔½░µ
wpe pro Alpha 0.9a ųą╬─ŠG╔½░µ




 Microsoft Spy++9.10 ųą╬─ŠG╔½░µ
Microsoft Spy++9.10 ųą╬─ŠG╔½░µ ╦╔Ž┬FPWIN GR(PLCŠÄ│╠▄ø╝■)2.94 ųą╬─░µ
╦╔Ž┬FPWIN GR(PLCŠÄ│╠▄ø╝■)2.94 ųą╬─░µ pip18.0 ╣┘ĘĮ░µ
pip18.0 ╣┘ĘĮ░µ ęūšZčį5.71═Ļš¹ŲŲĮŌ░µūŅą┬░µĪŠĖĮŲŲĮŌčaČĪĪ┐
ęūšZčį5.71═Ļš¹ŲŲĮŌ░µūŅą┬░µĪŠĖĮŲŲĮŌčaČĪĪ┐ ęūšZčįSHEŲż─w102┐Ņ+ā╚┤µŲż─w─ŻēK1.0 ŠG╔½├Ō┘M░µĪŠsheŲż─wųŲū„╣żŠ▀Ī┐
ęūšZčįSHEŲż─w102┐Ņ+ā╚┤µŲż─w─ŻēK1.0 ŠG╔½├Ō┘M░µĪŠsheŲż─wųŲū„╣żŠ▀Ī┐ lg plcŠÄ│╠▄ø╝■1.3 ūŅą┬ŠG╔½░µ
lg plcŠÄ│╠▄ø╝■1.3 ūŅą┬ŠG╔½░µ Visual Basic |VB6.0Š½║å░µVB6.0Š½║å░µ
Visual Basic |VB6.0Š½║å░µVB6.0Š½║å░µ DLL▐DLib(DLL2Lib_äėæBÄņ▐DņoæBÄņĄ─▄ø╝■)1.1 ųą╬─å╬╬─╝■
DLL▐DLib(DLL2Lib_äėæBÄņ▐DņoæBÄņĄ─▄ø╝■)1.1 ųą╬─å╬╬─╝■ visual assist xŲŲĮŌ░µfor vs2010/vs2013
visual assist xŲŲĮŌ░µfor vs2010/vs2013 DevExpress ŲŲĮŌ╣żŠ▀15.1 ŠG╔½ūŅą┬░µ
DevExpress ŲŲĮŌ╣żŠ▀15.1 ŠG╔½ūŅą┬░µ